引き続き、ドキュメントのある Blender2.6a をベースにコードリーディングを進めます。
Blender 内の動作を確認する
デバッガで動作を確認する
- Blender を Debug 版でビルドする
- 起動
- Visual Studio(VS) で デバッグ/プロセスへアタッチ
これで Blender と VS が接続された。
ブレークポイントを張ってみる
とりあえず適当にブレークポイントを張って、Blender の挙動を確認してみる。
コードをざっと見て bf_blenkernel に mesh.c というのがあったので、そこの add_mesh が Blender でジオメトリを作成するときに呼ばれる関数だろうという目星をつけてブレークポイントを張る。
Space→Add Cube で Cube を作成しようとすると、ブレークポイントで処理が止まって各種情報を確認できるようになる。
call stack を辿っていくと add_primitive_cube_exec() が呼ばれていて、更に呼び出し元を辿ると wm_* 関数群まで戻る。このあたりが GUI のメニュー処理を行っている。
wm_* 内で引き継がれている引数 ot がメニューと実際の処理を紐付けるためのもので、この中にどのメニューの表示内容やメニューが選ばれたときに呼ばれる関数がまとめられている。
このようにして、特定の機能やコードを起点にその周囲の処理の流れを把握することができる。
このときの情報を元に、次にどの方向に進むかを考える。今回の情報だけでも
- ジオメトリの生成や管理
- GUI でのイベント処理
- ot を中心としたイベント、メニュー、処理のテーブル管理
- テーブル管理のためのアーキテクチャ
といった方向性に進んでいくことができる。
Blender 内の構造を確認する
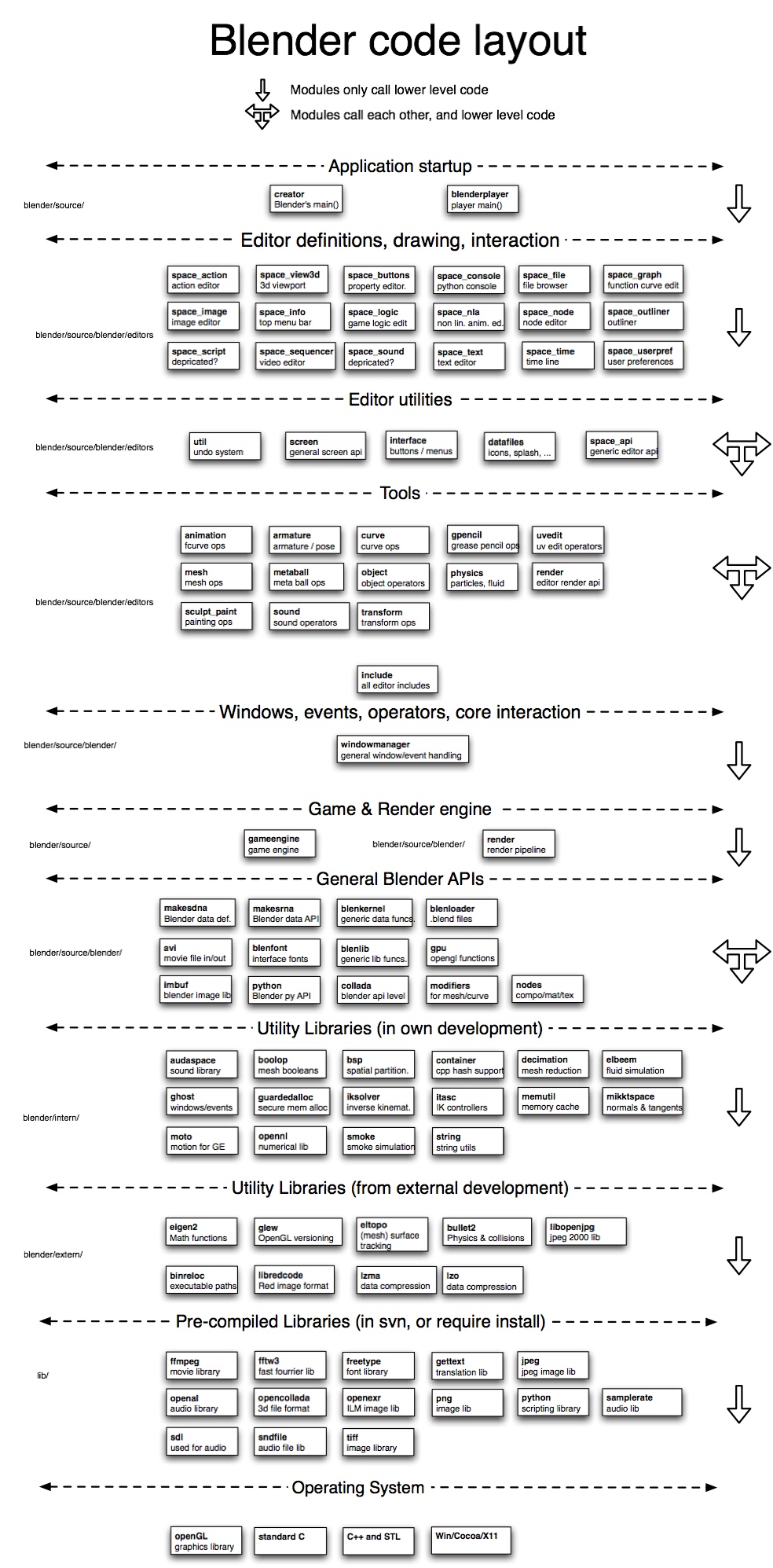
Blender code layout を見ながらコードのレイアウトを確認する。
横方向の点線でレイヤが分けられていて、矢印でレイヤ間/レイヤ内の依存関係が示されている。
Application startup レイヤ
例として Application startup レイヤの説明をおこなう。Application startup レイヤは blender/source ディレクトリにあり、creator と blenderplayer モジュールから構成されている。この二つのモジュールは依存関係がなく、それぞれは “Editor definitions, drawing, interaction” 以下のレイヤの機能を呼び出している。
モジュールの複雑さ
全てのレイヤは基本的に下のレイヤに依存しているため、上位に行けば行くほど複雑に、逆に下位に行けば行くほどそれぞれのモジュールの機能はシンプルになっていることが想像できる。
図をボヤッと見ていてもどこから手をつけていけばわからないが、タイトル下部に書いてある矢印の図を参考に、下の方から見ていくのがコツ。
Utility Libraries(in own development)レイヤ
Utility Libraries(from external development)レイヤ以下は外部で開発されている共通ライブラリなので今回のコードリーディングの対象にはならない。興味があればそれぞれのライブラリのプロジェクトを調べ、個別に調査をする。
つまり、Blender が抱えるコードで最もシンプルなのはUtility Libraries(in own development)レイヤに所属するものということになるので、まずはここの構造を把握することから始める。
モジュール概観
このレイヤに所属するモジュールをざっと眺めてみる
- メモリ管理
- 文字列処理
- 数値解析
- シーンデータ管理
- データ処理・ソルバー
- audaspace
- boolop
- decimation
- elbeem
- iksolver
- itasc
- smoke
- mikktspace
- moto
- システム・GUI
分類としては色々雑なものの、以上のような感じ。
このように同じレイヤ内でも全く異なる目的だったり、アプリケーション上での位置付けが異なるのものが並列して記述されているので要注意。ただ、このレイヤはあくまでもユーティリティライブラリなので直接 Blender の特定の機能と結びつくものではなく、汎用的な部品の扱いとなる。
また、モジュール一つ一つが VS のプロジェクトとして分けられている。例えば、smoke は bf_intern_smoke プロジェクトになっているので、ここのコードを辿れば Blender で使用している smoke solver の情報を得ることができる。
今回のまとめ
Blender の内部を解析するにあたって、実際の Blender の挙動から処理の流れを追う方法と、コードレイアウトのドキュメントから Blender の構造を把握する方法の二つの方法をおこなった。この二つの方法を用いることで、アプリケーションの構造を把握するための糸口を掴むことができるようになる。
引き続き、Blender Architecture を参考にしながら Blender の論理的な構造を探っていく。





{kind=link}
{kind=link}